Intro
Precoolers 是非常積極進取的,除了公司的業務外,更積極參加各界人士共襄盛舉的讀書會。這個知名的 (?)讀書會在2019年下半年開始高度關注假新聞的議題,因此假新聞與資料科學之間的關係與實務案例成了 Precoolers 茶餘飯後的話題(痾~最近有點消化不良)。
一邁進2020年,Precoo 就攜手端傳媒進行新聞報導的內容取材,近期更有不少專案與假新聞相關。其實假新聞早就不是新議題,其發展幾乎是跟新聞學一樣久遠,只不過英國脫歐以及後來劍橋分析事件之後,假新聞成為了熱門話題,研究假新聞更成為顯學。導致最近一波假新聞狂潮的原因不外乎是新媒體、社交網路等的盛行,讓訊息傳播沒有空間上的距離(只有與惡的距離?)。於是新聞生態有了一個全新的樣貌,而假新聞狂潮更已嚴重威脅到政治、新聞生態以及言論自由。在眾多與假新聞相關的數據科學研究論文中,Precoolers 為您選讀一篇2018年出刊的論文,以一個深入淺出(艱澀難懂部分跳過)的方式讓您也可以初探假新聞中的資訊技術發展。文長慎讀~
Overview
假新聞的定義
廣義:Fake news is false news,
狹義:Fake news is intentionally and verifiably false news published by a news outlet.
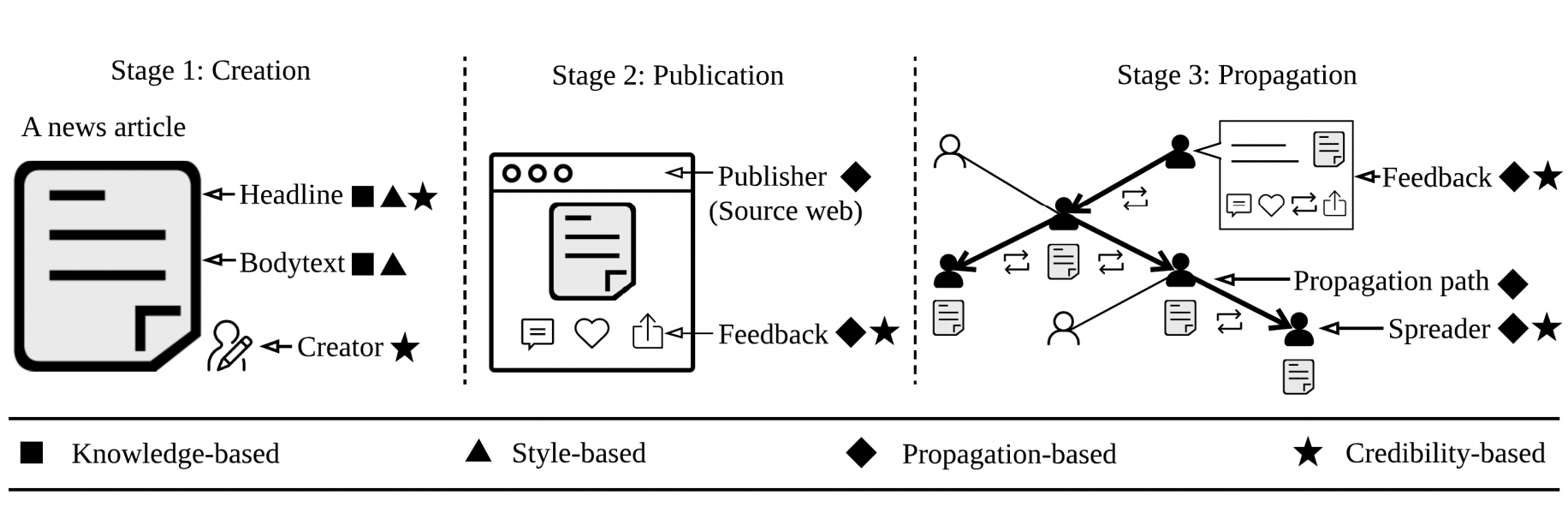
本篇論文以四個主要觀點為架構,提供量化、質化工具解析假新聞,甚至進一步提供偵測假新聞、介入假新聞的散播的策略。
- 以訊息內容為基礎(knowledge-based)分析假新聞中的錯誤訊息
- 以寫作風格為基礎(style-based)分析假新聞內容之撰寫模式
- 以政治宣導意圖為基礎(propagation-based)分析假新聞的傳播模式
- 以可信度為基礎(credibility-based)分析假新聞源頭及其散播者之可信度
以訊息內容為基礎之研究
Knowledge-Based Study Of Fake News
以訊息內容為基礎的研究主要就是針對新聞/訊息內容進行事實查核(fact-checking)。事實查核為新聞學的專業領域,是指為了確認真實性(authenticity)而針對內容進行確認。事實查核有兩種模式:人工查核(Manual fact-checking)或是自動監控(Automatic fact-checking)。
人工查核
可以分為專家查核(Expert-based Manual Fact-checking),例如PolitiFact,或是協同審核(Crowd-sourced Manual Fact-checking),例如Fiskkit。
補充:以台灣來說前者如TFC(台灣事實查核中心)後者如g0v推動的Cofacts真的假的專案。
自動監控
自動監控的開發需要資料檢索(IR)以及自然語言處理(NLP)技術來開發,相較於人工查核無法規模化資訊內容的事實查核,自動監控可以通過資訊技術來達成。
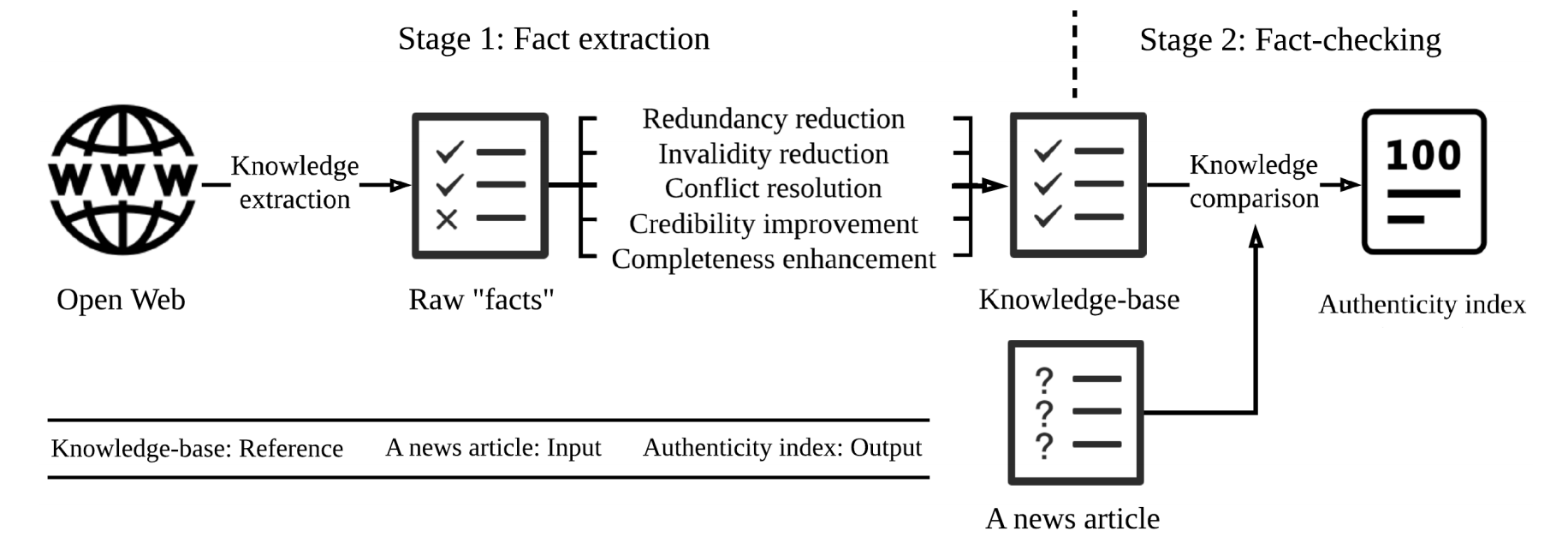
自動監控第一階段:資料擷取(Fact Extraction)
要進行事實查核就必須從開放網路(open web)中擷取原始資料(raw facts),過濾掉重複、過時、衝突、不完整等的原始資料後,才可以進行數據處理。
數據處理有以下主要任務:
- 實體辨識(Entity Resolution),其目標為辨識文字資料中指向實體(entity)的文字區塊,為資訊擷取的基本任務之一。
- 時間紀錄(Time Recording),某些資訊具時效性,因此事實查核時當然要檢核資訊發佈的時間點並過濾掉過時資料。
- 知識融合 (knowledge fusion)將多個數據源抽取的知識進行融合。如果原始資料是從不同來源擷取的,容易產生資料衝突,更應該進行知識融合。
- 可性度評估(Credibility Evaluation)透過分析來源網站的可信度來增加資訊的可信度。
- 連結預測(Link Prediction)可用來推斷新資訊、可預測實體間隱含的關係,下列可做為連結預測分析的模型。例如:latent feature models、graph feature models、Markov Random Field (MRF)models等。
知識庫(knowledge-base)建立
知識庫所儲存的資料已經是經過清洗並重建後的資料形式,比較常見的是SPO Triple。SPO是最簡單也是最靈活的一種儲存方式,以三元組(triple)架構知識圖譜(Knowledge Graph):主語─謂語─賓語,所有的連結都通過這種形式完成。
自動監控第二階段:事實查核
資料就緒之後,最後一步就是針對內容進行事實查核:
- 實體定位(Entity locating) 將主語及賓語(S/O)對應到知識圖譜上的節點(node)。
- 關係驗證(Relation verification) 指的是知識圖譜必須要是一個完整的triple,對應完成之兩個節點間的邊(edge)便是其間的關係。
- 知識推導(Knowledge inference)是當triple沒有被完整定義時,必須要透過預測連結(link prediction)來推導。
以寫作風格為基礎之研究
Style-Based Study Of Fake News
前段介紹的 Knowledge-based studies 主要在評估新聞資訊內容的正確性,而 Style-based studies 主要在偵測新聞資訊背後的動機(是否為惡意)。
本篇論文對於不實內容之研究(deception studies)有三個重點:
- 理論基礎
- 寫作風格式之特徵與模式(Style-based Features and Patterns)
- 不實內容之偵測策略
- 新聞中不實內容之偵測應用
理論基礎
大家都會直覺性地認為不實內容與真實訊息之撰寫模式應該會有所不同,而法律心理學(Forensic psychological)的研究已經證實這個說法。透過撰寫模式所偵測到的不實訊息,在研究結果上有高達60-90%的準確度。
寫作風格式之特徵與模式
總體上的特徵可以分為兩大類,以下表總結兩者:

不實內容之偵測策略
目前最普遍的策略都是利用特徵(feature)作為分析內容的維度,截至本篇論文發布為止,大部分的研究都是採取監督式學習(suprivsed learning),透過標註訊息為不實(deception)或一般訊息(normal)後訓練機器學習。因此,本篇論文只比較監督式學習的架構之研究表現,詳細內容可參考原文。
新聞中不實內容之偵測應用
分析新聞中之不實內容時有幾項重點:
- 大多數的理論基礎建立於法律心理學上,部分理論並無法有效判別出不實新聞。因此,需要更多新聞學之相關理論來支持。
補充:以 uncertainty 為例,其中一個特徵為計算內容中之問句數量,然而新聞是以事實報導為出發點,比起其他形式內容,新聞用語上的問句本來就相對少。 - 新聞內容通常是跨領域、跨語言甚至是跨議題的報導,由於文學中較少此類的研究,然而此類研究對於寫作風格研究是非常必要的。
- 通常不實新聞的爆發與大型事件有關(e.g. 選舉、COVID-19),因此大多數散播源頭都有強大的經濟支援,而這類即時的、突發性的發展通常都較難被偵測。因此,透過深度學習(deep learning)來做即時的監控是必要的。
偵測新聞中之不實內容時有幾項重點:
一般的基礎理論都可以應用於偵測新聞中之不實內容,比較重要的是半監督式學習的應用,原因有三。一是目前已標註的資料庫量並不多,二是無法定下黃金標準(golden-standard),最後是因為人工標註的資料量無法規模化。因此採納半監督式學習是必要的。
補充:研究證明人類辨別假新聞的準確率只有 55~58%,比用猜的機率高一點而已,因此人類無法告訴電腦怎樣是標準der。
中場小結
假新聞雖然不是新議題,但利用資料科學的手段來分析與偵測是相較新的研究,因此所有的框架與方法都值得一再探討。中場以這兩個分析觀點作收,歡迎讀者一起思考與討論!中場過後再讓我們一起看下去~