以政治宣導意圖為基礎之研究
Propaganda-Based Study Of Fake News
有別於前面兩段針對內容的分析與偵測,本段著重在分析訊息如何被惡意利用以及如何傳播。
根據假新聞相關的研究,可以將假新聞的傳播歸納出兩類模型:以事件或以時間為基礎。下表內兩張圖為例,最一開始的節點皆為假新聞的始作俑者,而其他節點代表轉發、分享該篇假新聞的使用者。
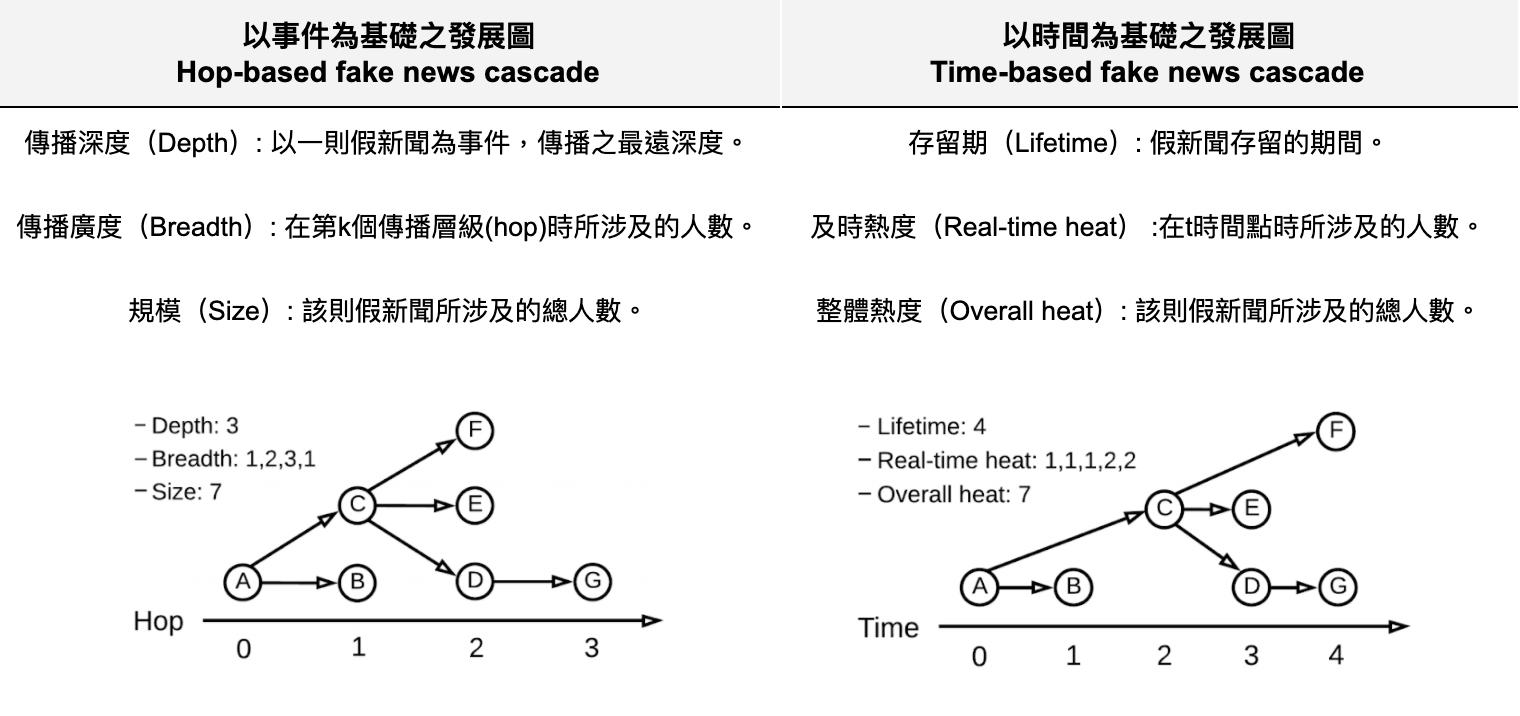
政治宣導之假新聞模式
假新聞的政治宣導模式有幾項重點:
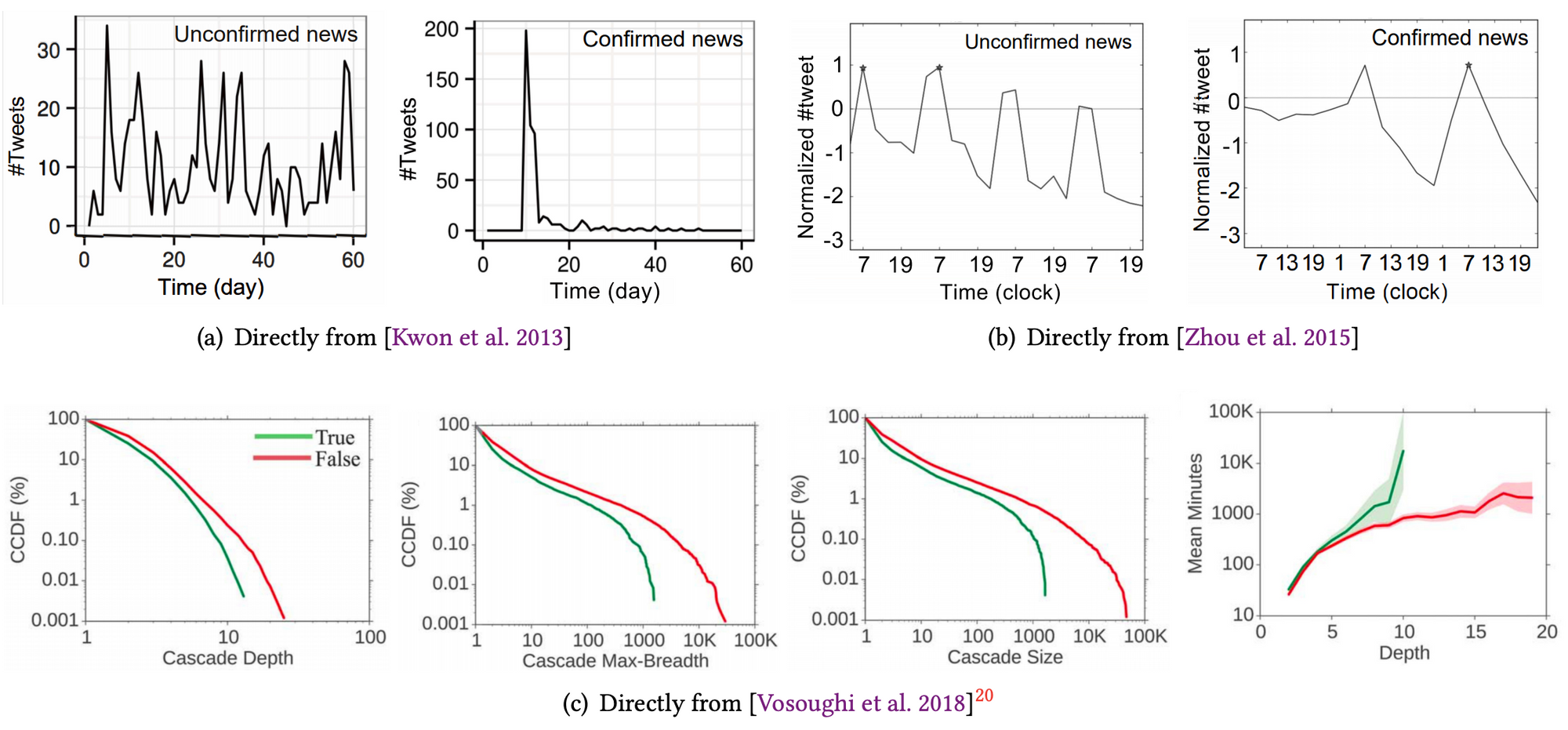
- 未證實過的假新聞會被不斷炒作,反之,被澄清後的假新聞會在澄清過後熱度銳減(如圖a)。若於一天內成功控制假新聞的擴散(此指文章數量),假新聞防治的效果較好(見圖b)。
- 如圖c,假新聞的傳播比真實新聞更快、更遠。而政治新聞比其他類型新聞更甚,與圖c假新聞比真實新聞的差異雷同。
政治宣導之假新聞模型
量化假新聞模式有幾個可行的數學模型:
- 迴歸分析(Regression analysis):比較經典的模型有線性迴歸、泊松迴歸(Poisson regression)、迴歸樹(Regression trees)等。
- 疫情擴散模型(Epidemics diffusion model):由於假新聞的傳播與傳染性疾病的擴散有不少相似特性,利用這個模型可以適當地預測假新聞的整體熱度。

- 經濟相關模型:假新聞操作可以視為一個策略遊戲,這遊戲中有兩派玩家:發佈者與消費者。所以可以透過策略遊戲的理論,預測使用者的決策與行為。
政治宣導之假新聞偵測
- 以瀑布流為基礎之偵測(Cascade-based Fake News Detection)
若以瀑布流為基礎偵測假新聞,有兩種方式,一是計算瀑布流的相似度,二是使用訊息性表徵(informative representation)判別真假新聞之差異:-
計算瀑布流的相似度
Graph kernels 是最常被拿來計算瀑布流相似度的方法,這種方法即是將某個新聞發展視為一個瀑布流(或是一個 graph),並將計算瀑布流間之相似度視為 features 加以監督式學習去偵測假新聞。文中舉例Wu et al. [2015]提出以Graph kernals 為基礎結合 SVM 分類並加上語意特徵(setimantic features)分析所提出的架構如下圖a。 -
使用訊息性表徵
在設計瀑布流表徵時必須套用適切的訊息性表徵,並將這些表徵視為監督式學習的 features。文中舉例 Cho et al. [2014] 則是利用一個 top-down 的遞歸神經網路以及其變形架構 Gated Recurrent Unites (GRUs),如下圖b結構。
-
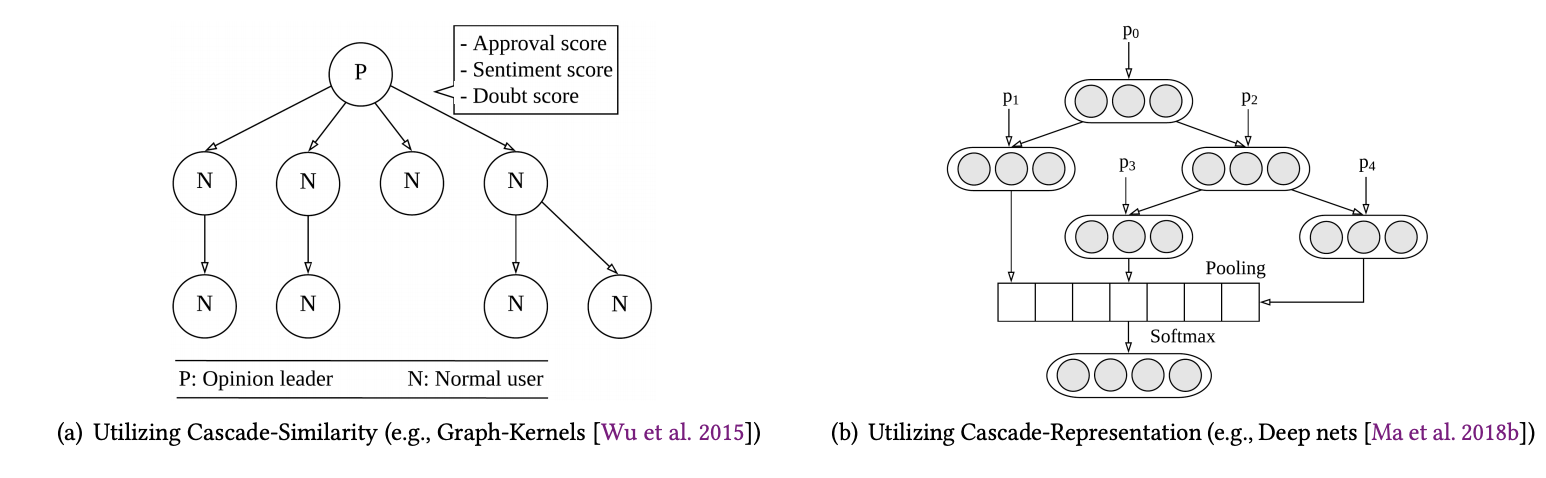
上述兩個以瀑布流為基礎的偵測,前者(計算相似度)的優點是可以在這樣的架構下進一步探討使用者於新聞傳播中所扮演的角色,不過計算瀑布流間的相似度卻會耗費大量運算資源。而後者(訊息性表徵)可以自動代入尚未被證實的新聞,然而瀑布流的傳播深度(depth)定義了深度學習的深度,當傳播深度越廣,深度學習的訓練也將更困難。
- 以網路為基礎之偵測(Network-based Fake News Detection)
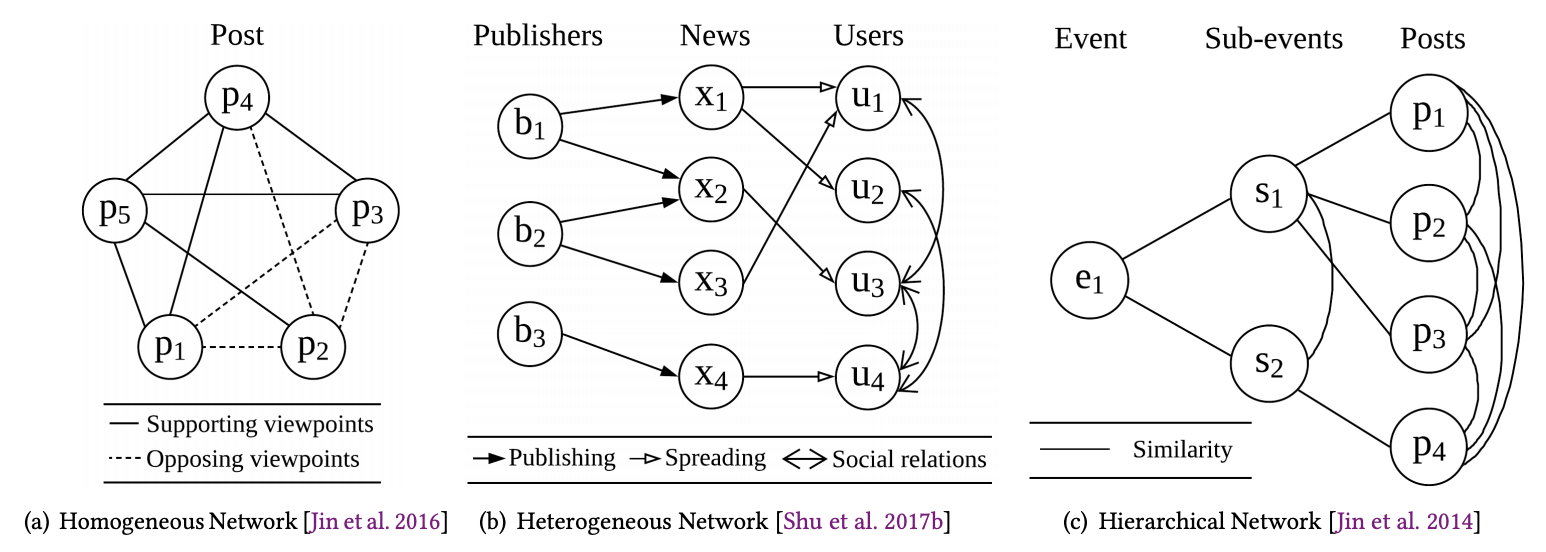
以網路為基礎之偵測會是相較彈性的架構,此類型的偵測有同質(homogeneous)、異質(heterogeneous)以及階級(hierarchical)網路。-
同質網路
同質網路只有一種節點一種邊。最典型的網路結構中,節點代表新聞或相關發文,而邊則代表文章間的支持/反對關係。使用這種模型說到底就是要找出那些可信度低的文章=極可能為假新聞。此方法建構於基礎的圖譜上,因此圖譜的最佳化(graph optimization)亦是重點。 -
異質網路
異質網路相較於同質網路有多種節點多種邊。典型的結構中的節點有新聞發布者、新聞文章以及新聞傳播者,因此可以分析三者間的相關性。更多異質網路的應用請見原文。 -
階級網路
階級網路中同樣有多種節點多種邊。階級網路中可以呈現階級關係、以及階級中的事件關係(如同質網路),而與同質網路相同,圖譜的最佳化(graph optimization)亦是重點。
-
以可信度為基礎之研究
CREDIBILITY-BASED STUDY OF FAKE NEWS
新聞的可信度研究是基於新聞、社群媒體相關之訊息內容,去分析其來源與發佈者的可信度(故此段研究內容部分程度與前段政治意圖為基礎之研究重疊),本篇論文從四個條件來看新聞的可信度:
- 新聞標題(headlines)
- 新聞來源(Source)
- 新聞留言(comments)
- 新聞散播者(spreaders)
新聞標題
透過新聞標題評估該則新聞是否為假新聞,其作法與一般偵測釣魚網站的做法類似。釣魚網站在社群媒體上已發展了一陣子,也因此社群媒體的網站陸續祭出規範來限制。值得注意的是,釣魚網站固然是不值得信任的來源,但其內容未必是假新聞。因此,後續的做法就與寫作風格為基礎之偵測雷同。
就新聞標題分析其新聞可信度,可透過下列兩種特徵加以監督式學習的架構進行偵測。
- 從語言特徵來分析,例如特定詞語的使用頻率、可讀性(readability)以及向前參考(forward reference)等。
- 從非語言特徵來分析,例如網頁連結(webpage links)、使用者興趣(user interests)以及標題立場(headline stance)等。
對於資料探勘和處理的問題,若使用一般的機器學習方法,需要提前做大量的特徵工程工作,而且特徵工程的好壞決定效果的優劣(也就是常說的一句話:資料和特徵決定了機器學習的上限,而模型和演算法只是逼近這個上限而已)。
論文中還有提到一點是,為避免利用特徵工程,近來有興起使用深度學習(deap learning)的趨勢。
補充:由於特徵工程會提前做大量的特徵工程工作,而這前期的特徵工程工作決定了機器學期的上限,很大程度影響了最後的分析結果。因此,許多人提倡利用深度學習取代之,因為它可以自動完成傳統機器學習演算法中需要特徵工程才能實現的任務,
新聞來源
有證據指出,大多數的不實訊息都是從假新聞網站或者是極端支持者網站(hyperpartisan websites)散布出來的,因此某種程度來說,一篇新聞的品質與可信度取決於其來源網站是否有文章品質保證、是否有高可信度、是否具有政治傾向等。
近來網站可信度分析是一個頗活躍的領域,因此產生了許多網頁可信度評分的演算法,舉例來說,比較傳統式的評分運算法如 PageRank, HITS 等。惟其評分方式反而促成了網路垃圾(web spam)的產生,網路垃圾偵測(web spam detect)又應運而生。
Web Spam的類型與偵測方法
- 內容 (content spam)
- 網路垃圾可以提高字數量使其網站於搜尋時出現,內容 spam 包含文章標題、內文、meta 標籤(meta-tags)、錨點超連結(anchor)以及URLs。
- 偵測演算法:計算其字數量、偵測內容重複度(content duplication)等。
- 連結 (link spam)
- 創造導出連結(outgoing link)網站會盡力滿足如 HITS 此類的演算法的標準,創造該網站的分數,而另一方面創造導入連結(incoming link)則會針對在 PageRank 這類的演算法中鑽漏洞。
- 偵測演算法:圖譜(graph)、統計異常(statistical anomalies)等技術。
- 其他
- 其他 spam 類型有隱形頁面(cloaking)、轉址(redirection)以及點擊(click spam)等。
- 偵測演算法:多基於 click stream、使用者行為的基礎上,然而特別著重於假新聞偵測的可信度分析演算法並沒有特別多,唯有部分網站開發中。
新聞留言
分析使用者的留言內容可以同時分析使用者的立場與觀點,近來假新聞的研究很少談論到新聞留言內容的分析,又即便分析了內容卻往往沒有進一步分析其可信度。一篇新聞底下若有許多反對言論,則容易遭受惡意攻擊,相反地,底下若有許多讚賞與支持,則可能吸引“假支持者”(fake supporter)。電商網站亦如此,常常需要分析、理解產品或網頁中使用者的留言,也因此電商領域對於垃圾留言(review spam)的研究已相當多。因此本篇論文將電商領域的做法與新聞留言分析一併探討。
- 分析留言內容之模型(content-based model)
同“以寫作風格為基礎之研究”方法相同,這邊就不贅述。 - 分析行為之模型(behavior-based model)
本篇論文作者比較了其他論文研究,總結了五個分析行為的要點:- 突發性(burstiness):評估評論者(reviewer)對於一個產品突然高分/低分評論的平均值、評論的數量等。這個類型指的是集體行為(collective behavior)。
- 事件(Activity):評估於一個時間區間內,同一評論者對於單一產品/多個產品的評論總數或者最多評論數。這個類型指的是個人行為(individual behavior)。
- 時間點(timeliness):評估一個產品最早的評論時間點。
- 同質性(similarity):評估同一評論者有多篇相似度極高/幾乎一致的評論、多個評論者對於單一產品有多篇相似度極高/幾乎一致的評論。或者是單一產品中評論者的偏差值(derivation)。
- 極端性(extremity):評估單一產品極端言論(最好與最糟)的比例/數量,或者同一個評論者對於不同產品之極端言論的比例/數量。
- 分析圖譜之模型(graph-based model)
列舉可能作為分析圖譜的模型,欲了解各模型之實作可以參考原文中引用的其他論文。- Probabilistic Graphical Models (PGMs)
- Web ranking algorithms and centrality measures
- Matrix Decomposition
新聞散播者
假新聞研究通常將所有使用者分為不懷好意的人(malicious users)與一般人(normal users),然而一般人也可能在無意中分享了錯誤的訊息,因此本篇研究將所有使用者分為參與者(participents)與非參與者(non-participents),非參與者當然就不在我們討論的範圍內,而參與者又可進一步細分為不懷好意的人(malicious users)與天真的人(naive users)。
-
不懷好意的人:具有惡意散播假新聞動機的人
- 機器人(bot)
- 酸民(troll)
- 假帳號(cyborg)
近來有研究指出可以透過行為模式(behavior pattern)判定該散播者為機器人還是酸民。也可分析個人頁面、發文行為以及內容去自動判斷該帳號是真人、機器人還是假帳號。若無法指認出這些惡意攻擊的人,便無法進一步觀察、防禦甚至是封鎖他們。
-
天真的人:無意間散播假新聞的人
天真的人可能是因為心理因素而影響決定進而無意間散播假新聞。- 社群影響(social influence):社群結構(network structure)或者同儕壓力(peer pressure)
- 自我因素(self influence):確認偏誤(confimation bias)或朴素實在論(naive realism)
然而近期分析假新聞的研究中,極少論及如何指認天真散播者以及他們所可能創造的影響力。
Summary
呼~我們用了如此大的篇幅介紹假新聞偵測面向以及偵測方法,惟假新聞仍是一個研究中的議題,許多方法還需要優化、許多理論仍等待實證,假新聞從古至今一直存在,依當代的媒體傳播媒介而有不同偵測方法與對策。我們這個世代的網路活動還在持續發展中,想必偵測、打擊網路假新聞還有很長一段時間。以下挑出文中總結的幾個重點與大家一起討論:
-
早期偵測的必要性與困難度
早期偵測是指,在一則虛假新聞尚未被廣為傳播時就能偵測到該新聞。許多論文都指出,當假新聞被傳播的越深、越遠,人們就越信任其內容,導致後續的澄清與處置都困難重重。然而早期偵測有其困難度。舉例來說,feature不會恆真,昨天是對的資訊可能在未來是錯的,反之亦然,因此要根據時事頻繁更新feature。另外還有一個重點是,早期偵測不可能是地毯式的偵測,只能決定一些方向與議題,再投入資源。
-
決定值得偵測的內容
什麼是值得偵測的內容?可能對社會帶來極大影響性的?亦或者是在過去經驗中發現容易被誤導成假新聞的?文中雖提出這兩個決定條件,但其實沒有正確答案,比如說公部門與私部門在決策時的衡量要素理當不同。
原文中當然還有許多實作上的討論,有興趣的讀者不妨花時間閱讀一下!下課!